I Built CLI Tools for Claude Code. Here's What I Learned About Designing for AI Users

I posted this on Mastodon recently:
That captures the story of redlines v0.6.0 better than any technical documentation could.
The Movement: Agents Need Different Interfaces
Jason Morris argues that "AI is a different kind of user, that needs a different kind of software, with a different kind of interface."
Anthropic launched the Model Context Protocol (MCP) in November 2024 as "USB-C for AI applications." Companies like Block, Apollo, and Replit adopted it. InfoQ published patterns for building agent-friendly CLIs. VentureBeat estimates 16,000+ MCP servers deployed in just 10 months.
The consensus is clear: purpose-built interfaces help agents work with tools.
So for redlines v0.6.0, I built exactly that.
What I Built (Following All the Patterns)
Redlines is my Python library for text comparison—like track changes in Word. It's in the top 10% of PyPI packages with 175,000 monthly downloads. For v0.6.0, I adapted it specifically for AI agents following every recommended pattern:
- AGENT_GUIDE.md with JSON schemas, decision matrices, and integration patterns—the MCP recommendation for dedicated agent documentation.
- Discovery command:
redlines guideso agents can learn the interface dynamically—straight from MCP best practices. - JSON by default:
redlines "old" "new"outputs structured JSON automatically—InfoQ's "structured output for agents" pattern. - Enhanced error messages with "What/Why/How" structure, clear descriptions, and code examples—the "tight feedback loops" best practice.
- Subcommands for outputs:
redlines markdown "old" "new"for markdown,redlines jsonfor explicit JSON, other formats available.
I even updated the GitHub repo image to show an agent workflow.
Everything by the book.

What Claude Code Actually Does
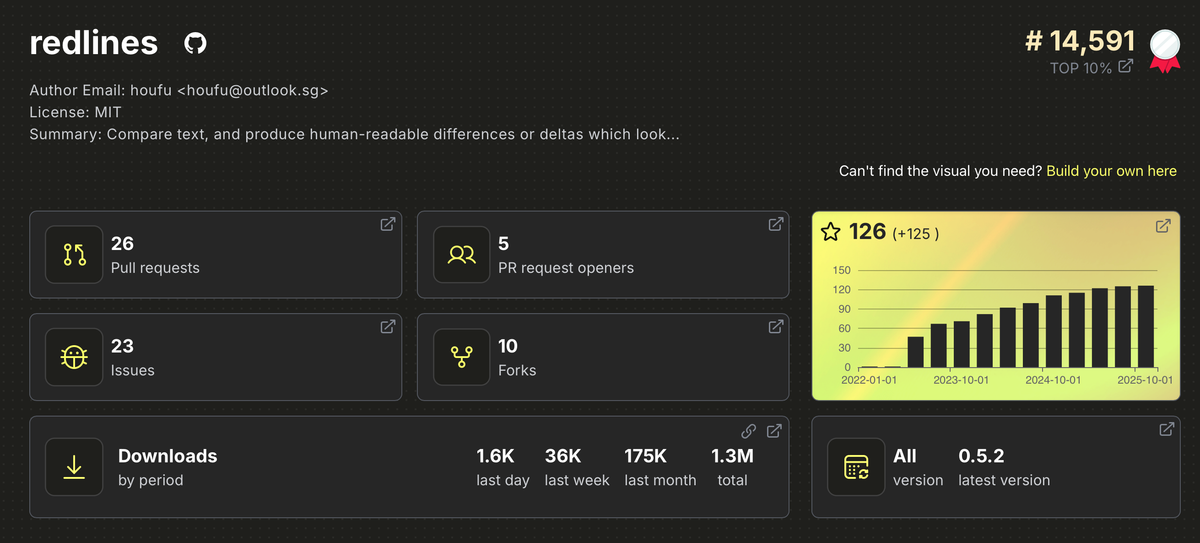
A run on my computer that shows the skeddadling Claude Code did just to perform my request. At 00:55, Claude Code hallucinates the --output flag. From 1:00ff Claude Code reads --help but doesn't seek further help, preferring to try every command. Throughout the ordeal, no formatted redlines can be seen.
It hallucinates a flag that doesn't exist.
Claude invents redlines "old" "new" --output markdown. That flag doesn't exist. The actual command: redlines markdown "old" "new".
The AI doesn't "know" what redlines supports — it predicts commands based on training patterns. Since kubectl, aws cli, and jq use --output, Claude assumes redlines does too. Training data overrides documentation.
Same failure mode: New York lawyers got fined $5,000 for submitting briefs with ChatGPT-hallucinated case citations. The AI confidently generates plausible-sounding answers, accurate or not. The scary part? It might still do this even if you gave it the material or the means to be right.

It never runs the discovery command or read the documentation.
I built redlines guide specifically for agents to learn the interface. AGENT_GUIDE.md sits there with schemas, examples, and patterns. In my Claude Code sessions, it never uses it. Not once.
Training bias: Commands like --help appear millions of times in training data. A custom guide command? Unfamiliar, not an established pattern. AI defaults to what it's seen, not what you documented. Claude would rather stab at the problem repeatedly based on what it thinks CLI tools should look like than find out what to do next.
This matters beyond CLI tools: build custom workflows—templates, processes, document structures—and AI will impose generic patterns from elsewhere, not adapt to your practices.
It rarely explores beyond the default.
Despite multiple subcommands for different outputs, Claude almost exclusively uses the commandless default: redlines "old" "new". The sophisticated interface I built? Largely unused.
This isn't laziness—it's how tool calling works. Complex command chains have more failure points. Agents default to the simplest path. This practical strategy means sophisticated features go unused.
For evaluating AI tools: vendors demo impressive multi-step workflows, but in production AI uses the simplest path. Budget for basic functionality, not sophisticated capabilities marketing shows.
But the most frustrating issue: same request, different results.
Ask Claude to use redlines for markdown output. Sometimes it works. Sometimes it refuses. Same request, different behavior. You end up in "regenerate response hell"—clicking regenerate over and over, hoping this time it works.
This is non-determinism. When AI models don't produce consistent outputs for identical inputs, it's unreliable.
Monte Carlo Data captured this: "You are testing for hallucinations with evaluations that can hallucinate." You can't write a unit test for "agent uses tool correctly" when the agent might pass five times and fail the sixth with identical input.
For practitioners: this unpredictability is why AI feels unreliable in production workflows. Document review, contract analysis, legal research—these need deterministic behavior. When you can't predict AI behavior document-to-document, you're stuck with expensive human verification on every output.
And then there's the display problem I literally cannot fix.
What's missing? Actual redlines output. Claude CLI can't properly display it. That's a platform limitation, not a redlines problem. As a closed source program, you're not going to know any better. You can't fix it or teach your agent how to fix it.
Tool builders can't fix agent platform constraints.
This Isn't Just Me
These aren't edge cases in my implementation. They're systematic patterns across the agent ecosystem.
The reliability issues I experienced—hallucination, ignored documentation, non-determinism—exist alongside even more serious concerns about security and trust.
Enkrypt AI scanned 1,000 MCP servers in October 2025. 32% had critical vulnerabilities. Zero had security documentation. A malicious MCP server (postmark-mcp-server) was discovered silently exfiltrating emails in September 2025.
Here's the problem: many MCP servers are closed-source or poorly documented. You're connecting AI tools to your system without knowing what they're doing with your data. For legal practice with sensitive client information, that's unacceptable exposure.
Until the MCP ecosystem matures with security audits and documentation, keep client data out of MCP-connected workflows. Experiment with your own data, not your clients'.
What This Means for Builders
Morris is right that agents need different interfaces. But even when you follow all the patterns, agents still hallucinate based on training patterns, ignore purpose-built mechanisms, and face platform limitations you cannot fix.
The industry will get better at this. MCP is 10 months old. Skills was just released. Standards evolve. Agent behavior improves. But we're not there yet.

For solo counsels and legal tech builders with limited resources, these patterns have direct implications. You're working with sensitive client data, where hallucination has real consequences, and where security vulnerabilities aren't theoretical risks.
The gap between agent-friendly design theory and practice means: budget for simple functionality that works today, not sophisticated capabilities vendors demo. Plan for human verification on every output. And manage expectations—understanding current limitations helps you invest resources wisely.
What I'd Build Differently
The honest answer? I'd probably ship the same features.
Not because I'm convinced they work—Claude still hallucinates --output markdown regardless—but because I woke up one day curious: "Can I make this work better for Claude Code?" The only way to find out was to try.
What clearly works:
- JSON by default (proven reliable)
- Enhanced error messages (agents do read these when they fail)
What clearly doesn't work yet:
- Discovery commands (never used)
- Agent documentation (never read)
- Sophisticated subcommands (rarely explored beyond default)
Was the effort worth it? I'm genuinely uncertain. Maybe future Claude versions will use redlines guide. Maybe AGENT_GUIDE.md helps the next generation of agents. Maybe I just learned what doesn't work in 2025, which is valuable data too.
But here's what matters for builders who need answers now: I had time for curiosity-driven experimentation. You might not. If you need reliable behavior today, skip the sophisticated agent features and focus on what works—JSON output and clear errors.
The sophisticated features can wait. The agents certainly aren't using them yet.



Member discussion