Half-Time on My 2026 Predictions: My Confidence Was Inverted

In January I made five predictions about legal AI, gave each a success criterion, and did one thing most prediction posts skip: I ranked my own confidence. Two I was most confident about. Two I flagged as most likely to fail.

My 2026 Legal AI Predictions (From the Trenches, Not the Boardroom)
Six months in, that ranking is almost perfectly inverted. The two I was surest of are my worst calls. One of the two I expected to fail became the story of the year.
That inversion — not any single grade — is what this halfway post is really about. First, a confession: I promised to track all of this publicly, month by month, in a repo anyone could watch. I didn't keep that log. Twenty-two published posts since January turned out to be a serviceable audit trail anyway — and the one log I did keep, a work log of my actual AI usage at the office, is where we have to start.
I was certainly wrong about my legal work
The bet: meaningful AI use across my legal work would stay under 20%. Friction is real, I said; the adoption headlines were inflated.
Reality: north of 50%.
Since May, that log puts AI in more than half my tasks. And that's on a strict bar for "meaningful" — not "asked a chatbot a question," but AI doing substantive work I'd otherwise do myself: reading, drafting, vetting, framing advice. I didn't just miss. I missed in the opposite direction, on the prediction I'd have bet the house on.
But here's the part worth more than the mea culpa. In January I set the industry's "adoption doubled to 52%" against my own "under 20%" — and those were never the same axis. 52% measured adoption — how many lawyers touch AI at all. My 20% measured intensity — how much of my work AI does.
You can be right that adoption claims are hype and run AI in half your tasks. What lost wasn't my arithmetic; it was the friction thesis. I bet workflow friction and client expectations would hold real usage down. By mid-2026 the tools had climbed inside the daily workflow, and friction stopped being decisive.
Why is this the confession and not the headline? Because being wrong that AI usage would stay low, in 2026, is the least surprising way to be wrong. The 8am 2026 report has adoption at 69%; Harvey reports 80% weekly usage. I doubted the trend and became a data point for it. Humbling — but not the interesting story.
The Word Plugin troubled me most
The bet: by year's end I'd complete routine contract reviews using only AI and agents, never opening Word.
Reality: fail at half-time — and I've thought about this one more than any of the others.
The prediction was never that a good tool would exist. It was about orchestration: agents operating the document while the human stays out of it entirely. Hold that definition, and the year's flood of Word plugins — Claude for Word the loudest of them — is not evidence for me. It's evidence against: if the AI lives in a sidebar inside Word, we never leave Word.

A community of lawyers who build agents — people whose default is to automate first and apologise later — reached the same verdict independently, and phrased it in a way that's been bothering me since: the agent moved into Word; the human didn't move out. Word didn't lose to the agents. It absorbed them. I'd been treating the format as a legacy constraint the agents would eventually route around. What if it's the gravity well they all fall into?
What keeps the bet breathing is the other direction of travel. Spellbook just announced Autonomous Contract Management — pointedly not a CLM (contract lifecycle management tool), they insist — with contracts "reviewed and redlined before a lawyer ever opens" them. Early access only, but the pitch is exactly my bet. I always expected the real work to happen somewhere like Cowork, not Word — and Microsoft's Copilot Cowork, generally available since mid-June, is a step on that axis. It shipped still unable to edit a Word file, though. The gravity well again.
The wall I keep hitting isn't capability. My agents' benchmark failures this year were packaging and delivery, not legal reasoning — the memo was right; the file was unopenable. What's missing is validation: I still open Word to check the agent's work, because I don't yet trust it enough not to. Until I can validate reliability without opening the file myself, the human hasn't actually left the app. So: fail. But I'm not conceding this one before December.
The story of the year: Prediction 2, the jagged frontier
The bet: the problem was never that AI fails — it's that we can't predict which tasks it'll fail at, and that unpredictability wouldn't improve in 2026. I flagged this as one of my two most likely to fail, because it was the hardest to pin down.
Reality: it's the prediction the evidence kept confirming — and I did not expect it to feature this heavily.
It kept showing up whether I invited it or not. In February, a benchmark called SkillsBench put numbers on it: across 7,308 agent runs, curated skills helped by 16 points on average — but 19% of tasks got worse.

Then my own benchmark run said it again from the inside: my lawyer-built stack won on extraction and comparison while collapsing on long-form drafting. Same tools, opposite results, no reliable way to know in advance.
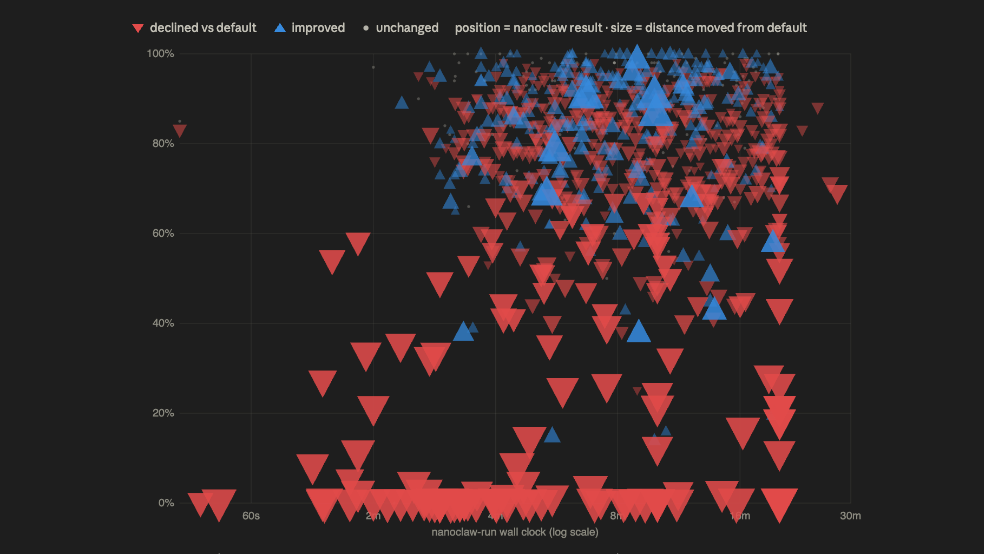
One correction on the deliverable, said plainly rather than quietly dropped. In January I promised a "revised decision framework" — a way to know when to trust AI. Six months of exactly this unpredictability convinced me: I'm retiring that promise. A hand-waved rule ("use AI for low-stakes, catchable tasks") is useless when the real variable is context. The genuine lesson turned out to be about harness design, not evaluation — if the failures live in the environment around the model, the fix lives in how you build that environment, not in a decision tree you consult beforehand.
And the truly uncomfortable finding sits under the confirmed prediction. The only rigorous way to actually map the frontier is a benchmark on synthetic data. I ran one. It took two weeks and burned my entire compute quota.
Which means the honest tool for navigating the jagged frontier is out of reach for exactly the resource-constrained practitioners this blog is written for. Being right about the frontier bought me nothing I can hand to a reader. That's a better thing to say than a framework I'd have to fake — and it's why this, not the big miss, is the story of the year.
Prediction 4: half right, on the wrong half
The bet: hallucinations stay unsolved in 2026, but maybe become manageable through structure — RAG with citations (grounding answers in pre-approved sources), two-pass review, locked templates. Another one I was most confident about.
Reality: the "unsolved" half holds. The "manageable" half is trending the wrong way — and I never ran the experiment.
I didn't run the three-workflow bake-off, and I'm not scheduling it now — real agent use answered the question the lab test would have asked, and less comfortably: the more I lean on autonomous agents, the worse the reliability problem gets. Every increment of autonomy widens the surface where things break — agents route around the tools I give them, ship confident output that's quietly wrong, and hand back finished legal work in a file nobody can open.

I aimed the paradox at the wrong target. I worried about the invented citation. The sharper 2026 risk is the well-formed deliverable that's subtly wrong, produced by an agent doing more and more on its own. Structure might still tame that — but six months of harder agent use has moved me toward pessimism, not comfort.
Prediction 5: holding, with a twist
**The bet:** most AI adoption would be checkbox theatre; real innovation would live in isolated pockets. I also bet *against*Salesforce's prediction that ASEAN, unburdened by legacy systems, would "leapfrog" into the agentic era. Another flagged-to-fail.
Reality: holding.
The innovation pockets were thinner than the press releases suggested — legal open source isn't a community, it's "a federation of solo-author archipelagos."

The counter-signal was close to home: two of my recommendations on MinLaw's draft AI guide landed in the final, near-verbatim. Real, public iteration that changed something.

On ASEAN: the region-wide leapfrog hasn't materialised. Theregional pictureis uneven — Singapore leads on legal-sector AI infrastructure, while Vietnam, of all places, beat everyone to a binding AI law. The barriers I pointed to —no training at 54% of firms, no policy at 43% — are exactly the non-legacy constraints I said would matter more than being "unburdened by old systems." The twist I didn't see: Singapore leaping while the rest of ASEAN lags is my own thesis in miniature — innovation in isolated pockets.
The scorecard, and what the inversion taught me
| # | Prediction | January confidence | Half-time verdict |
|---|---|---|---|
| 1 | Doc review, human out of Word | Optimistic (stretch) | Fail — but still fighting |
| 2 | Jagged frontier won't improve | Most likely to fail | Confirmed — the story of the year |
| 3 | Usage stays under 20% | Most confident | Wrong, in the opposite direction |
| 4 | Hallucination manageable | Most confident | Half wrong; trending worse |
| 5 | Mostly theatre | Most likely to fail | Holding |
I was calibrated the wrong way round: the predictions I'd have bet the house on are the two the year most thoroughly refuted; the ones I hedged as too hard to call are the ones that held.
I think I know why, and it isn't flattering. My confident predictions were the comfortable ones — they matched how I wanted 2026 to go: friction protecting us from over-reliance, structure taming the risk. My pessimistic predictions were the ones I'd already tested against reality and expected to lose. Comfort is a terrible forecasting input. The frontier doesn't care what would be convenient for me.
What happens now
The tracking failure was real, so here's the fix and not the excuse. I've back-filled the repo with what these six months actually showed, and for the rest of the year I'm swapping the fantasy of a perfect monthly spreadsheet for something I'll sustain: a short entry appended whenever a post touches a prediction. Lower friction, same audit trail, still public in the commits.
Two deliverables stand where I left them: the theatre-versus-innovation framework (Prediction 5) I intend to ship; the jagged-frontier decision framework (Prediction 2) I'm formally retiring, and I've told you why.
The $500 stake stands. The December scorecard stands. If anything, being this wrong at half-time makes December more interesting — the story was never going to be "did he call it." It's watching a guy find out his instincts were inside-out, in public, with the receipts.
See you in December with the data. All of it this time.




Member discussion