Building data.zeeker.sg: Technical Architecture

In Part 1, I shared the decision dilemma: 150+ hours building Singapore's first public legal news API, zero known users, and institutions entering the space. Should I continue or stop?
The data.zeeker.sg series
This is Part 1 of a 3-part series on building and potentially closing down data.zeeker.sg:
- Part 1: When Institutions Enter Your Space - The decision framework and where I am now
- Part 2: Technical Lessons (this post) - The full technical stack, what worked, what didn't, and how AI tools made solo infrastructure building feasible—for builders who want the implementation details
- Part 3: What I Learned at SMU + My Decision (coming after Nov 18) - What they're building, how I decided, and what happened next
Before making that decision, I want to document what I learned building this infrastructure. Whether data.zeeker.sg continues or not, these technical lessons are worth sharing—for solo builders considering similar projects, for lawyers curious about what legal data infrastructure requires, and for anyone wondering what's feasible for one person in the AI era.
Who This Post Is For
Reading time: 21-25 minutes
This post is technical—not "read the code" technical, but "understand the architecture and tradeoffs" technical.
You should read this if you:
- Are a lawyer who codes or legal technologist
- Build civic/legal tech with limited resources
- Want to understand what one person can build
- Are evaluating build vs. buy for legal data infrastructure
Skip to Part 3 if you:
- Want only the decision-making narrative without technical details
- Prefer high-level insights over implementation specifics
Reading Guide
Choose your path based on your time and interest:
Quick Strategic Overview (~10 minutes)
- Read the "Three Layers" section summaries
- Jump to "Design Decisions"
- Read the Conclusion
Architecture Understanding (~15 minutes)
- Read "Three Layers That Work Together"
- Read "Design Decisions: Why This Architecture?"
- Skip the detailed code examples (they're in collapsible sections)
Full Technical Deep-Dive (~25 minutes)
- Read everything
- Expand all code examples and technical details
- Best for builders planning similar projects
What You'll Learn
- The three-layer architecture that makes solo infrastructure building feasible
- Why specific tools (SQLite, Datasette, CLI-based workflows) enabled this project
- Design decisions that reduce ongoing maintenance burden
- Cost comparisons: $6-12/month vs. $45-95/month for traditional architecture
- How architectural choices enable open source contribution
The technical details inform the decision. Understanding what this project required—and what it could become—shapes whether it should continue.
Table of Contents
Three Layers That Work Together
Layer 1: Data Layer - The CLI Tool (~8 min)
- Why a CLI tool?
- Complete workflow & resource architecture
- Cost comparison: Infrastructure savings
- Multi-machine sync
Layer 2: API Layer - Datasette (~5 min)
- From SQLite to live API
- What you get automatically
- Continuous deployment flow
Layer 3: UX Layer - Making It Accessible (~4 min)
- Search-first interface
- Use-case driven examples
- Progressive disclosure
Design Decisions (~6 min)
- Why SQLite instead of PostgreSQL?
- Why Datasette instead of custom API?
- Why Datasette instead of CKAN?
- Why static deployment?
- Why this enables open source contribution
Conclusion (~2 min)
Technical Architecture: Three Layers That Work Together
Building data.zeeker.sg taught me something critical: modern infrastructure for legal data isn't just about collecting information. It's about making that data immediately useful to different audiences without requiring technical expertise.
Monthly cost: $6-12 (vs. $45-95 traditional)
Time per new source: 2-4 hours (vs. 8-14 hours)
Scaling to 40 sources: 240-400 hours saved
Maintenance: Minimal (GitHub Actions automation)
Infrastructure: Read-only, corruption-proof
The architecture has three layers:
- Data Layer - CLI tool that handles scraping, database scaffolding, and deployment
- API Layer - Datasette that turns SQLite into instant REST API + searchable interface
- UX Layer - Canned queries that make legal research accessible without SQL knowledge
Each layer solved a specific problem. Together, they created infrastructure that runs automatically and serves both developers (who want APIs) and lawyers (who want answers).
Let me walk through what each layer does and why it matters.
Layer 1: Data Layer - The CLI Tool
How standardization saves 240-400 hours when scaling from 1 to 40 sources
The problem: Scaling legal data sources without chaos
I started with one legal news aggregator, but I could already see the future problem: What happens when I want to add more sources?
Without standardization, each new source means:
- Writing custom scraping logic (RSS feeds, HTML parsing, APIs)
- Creating database tables with potentially different schemas
- Implementing error handling, logging, retry logic
- Setting up scheduling and deployment
- Maintaining N different Python scripts in N different ways
I built the zeeker CLI to solve this problem early. Standardize the pattern with one source first. Then scaling to many sources becomes trivial.
Why a CLI tool?
Two critical reasons:
1. Standardization across all data sources
The CLI enforces one pattern for everything:
- Unified interface: Every source implements
fetch_data()- that's it - Automatic schema management: Table creation, type inference, conflict detection
- Built-in error handling: Framework handles errors, not reimplemented for each source
- Consistent metadata: Every table gets identical tracking (last updated, record count, schema version)
I built one source this way. Adding the second, third, or fortieth source? Get the cli to generate the scaffold, write scraping logic, done. No reinventing infrastructure.
2. Automation & Continuous Deployment
CLI commands are scriptable:
# GitHub Actions workflow
zeeker build --sync-from-s3 # Incremental update
zeeker deploy # Push to S3Or schedule locally:
# Cron job: Daily at 2 AM
0 2 * * * cd /path/to/legal_news_sg && zeeker build && zeeker deployHuman-friendly commands + machine-friendly automation = sustainable infrastructure
Without the CLI, continuous deployment means writing custom orchestration scripts (code that coordinates multiple tasks). With the CLI, it's one line in a cron job or GitHub Action.
🔧 Complete CLI Workflow (expand for code examples)
The complete workflow:
# 1. Initialize a new database projectuv run zeeker init legal_news_sgcd legal_news_sg
# 2. Add a data resource (creates template with proper structure)uv run zeeker add articles --description "Singapore legal news articles" --facets category --facets jurisdiction --sort "published_date desc"
# 3. Implement your scraper in resources/articles.py
# (Screenshot will show the generated template)
# 4. Build the SQLite databaseuv run zeeker build
# 5. Deploy to S3uv run zeeker deploy
The resource-based architecture:
Each data source is a Python module implementing one function:
```
# resources/articles.py
from sqlite_utils.db import Table
from typing import Optional, List, Dict, Any
def fetch_data(existing_table: Optional[Table]) -> List[Dict[str, Any]]:
"""Fetch legal news articles from Singapore sources."""
# Your scraping logic here (requests, BeautifulSoup, APIs, etc.)
data = scrape_legal_news_sources()
# Incremental updates: filter out existing records
if existing_table:
existing_ids = {row["id"] for row in existing_table.rows}
data = [item for item in data if item["id"] not in existing_ids]
return data
```
SQLite as deployment artifact - The key insight:
Traditional approach:
- Run database server (PostgreSQL, MySQL)
- Scrapers insert data into live database
- Worry about concurrent writes, connection pooling (managing database connections efficiently), backups
- Deploy database separately from application
Zeeker approach:
- Build SQLite file locally (
zeeker build→legal_news_sg.db) - Push file to S3 (
zeeker deploy→ S3 static storage)
Results:
- No database server to maintain
- Atomic updates (new file replaces old)
- Version history for free (S3 keeps old versions)
Cheap hosting (S3 storage costs, not running servers)
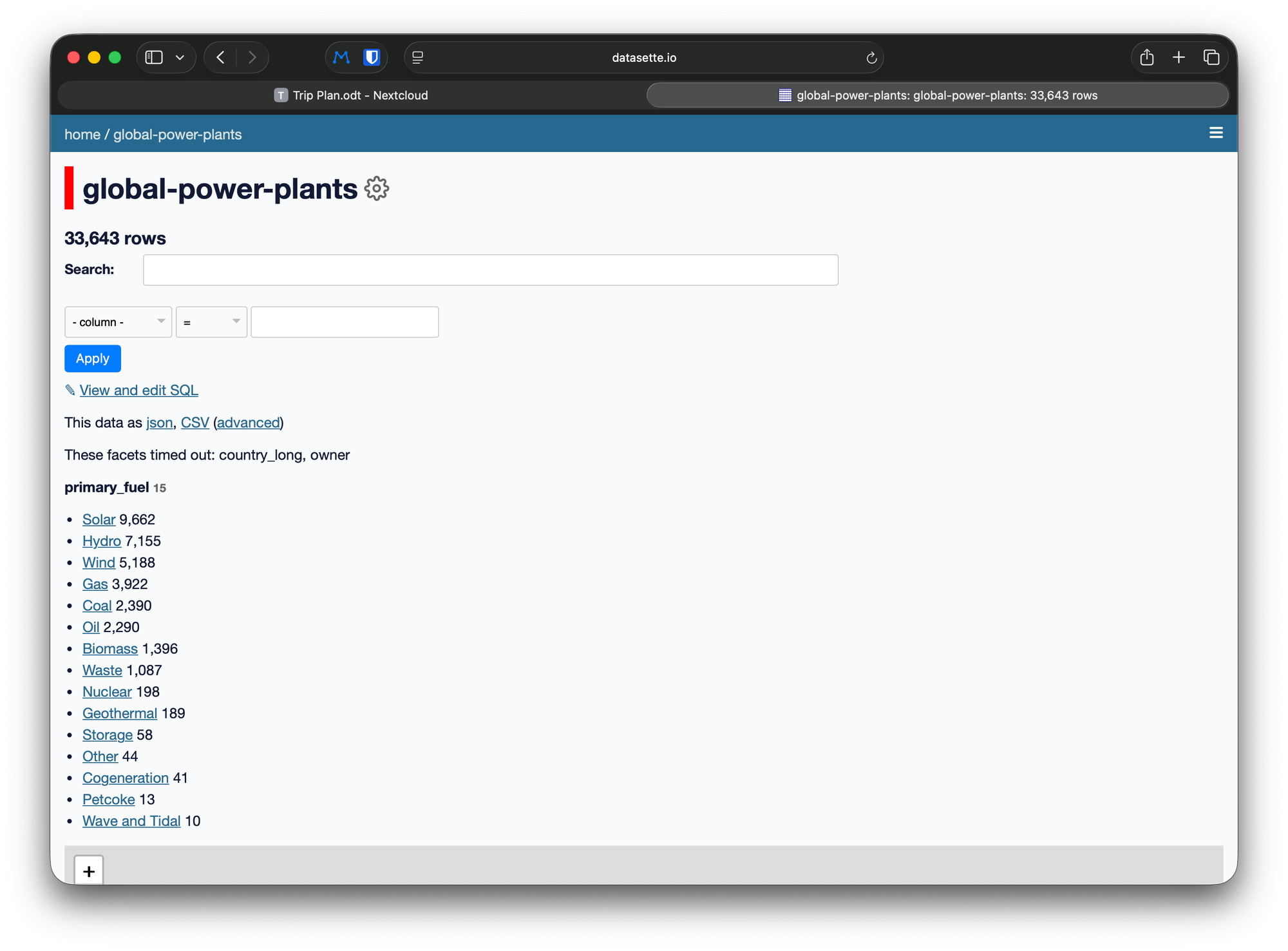
💰 Cost Comparison: Why This Architecture Matters
Building infrastructure for a passion project means every dollar and every hour counts. Here's the real cost difference:
Monthly Infrastructure Costs
Traditional SQL Backend Approach:
- RDS PostgreSQL (small instance): $15-30/month
- Application server (API + web): $10-25/month
- Scraper orchestration server (running scrapers on schedule): $20-40/month
- Can't use serverless efficiently - needs coordination
- Needs always-on container or VM for cron jobs
- Scales poorly as you add sources
- Backups, monitoring, security patches
- Total: $45-95/month + ongoing DevOps overhead
SQLite + S3 + GitHub Actions Approach (data.zeeker.sg):
- S3 storage (1GB database): $0.023/month
- S3 requests (reads via Datasette): ~$1-2/month
- Datasette hosting (single read-only container): $5-10/month
- Scraper orchestration: GitHub Actions free tier - serverless, zero cost
- Runs
zeeker build && zeeker deployon schedule - No always-on infrastructure needed
- Scales linearly with more sources
- Total: $6-12/month, minimal maintenance
The infrastructure saving: No server running 24/7 just to run scrapers. GitHub Actions executes when needed, shuts down when done. Whether you have 1 source or 40, costs stay flat.
⏱️ Developer Time: Adding a New Data Source
Traditional approach (without standardized tooling):
- Write scraper script: 2-4 hours
- Write database migration: 1-2 hours
- Update API endpoints: 2-3 hours
- Update deployment scripts: 1-2 hours
- Test and debug: 2-3 hours
- Total: 8-14 hours per new source
With zeeker CLI:
zeeker add source_name: 30 seconds- Implement
fetch_data()in generated template: 2-4 hours zeeker build && zeeker deploy: 2 minutes- Total: 2-4 hours per new source
Scaling to 40 sources: With standardization, that's 80-160 hours total vs. 320-560 hours without it. 240-400 hours saved (6-10 weeks of full-time work) by building the right foundation first.
For a solo builder working evenings and weekends, designing for standardization upfront—even with just one source—is what makes future scaling feasible at all.
Multi-machine sync for incremental updates:
# Machine A: Initial build
zeeker build
zeeker deploy
# Machine B: Sync existing data, add new records
zeeker build --sync-from-s3 # Downloads existing DB first
zeeker deploy # Uploads updated DB
# GitHub Actions: Daily automated updates
zeeker build --sync-from-s3 # Gets latest, adds new articles
zeeker deploy # Pushes updated DBSame commands work on your laptop, on a server, in CI/CD. That's the power of standardization.
For coders: Python-based CLI using Click, sqlite-utils for database operations, automatic schema detection and type inference, comprehensive pytest test coverage, modular command structure. Source: github.com/houfu/zeeker
For lawyers: One command (zeeker build && zeeker deploy) updates all your legal news sources and publishes the update. Schedule it daily, and your legal database stays current without manual intervention. No database administration required.
The output: A single SQLite file in S3, containing structured data with proper schema, metadata tracking, and ready to be served. How does that file become a searchable API and web interface? That's where Datasette comes in.
Layer 2: API Layer - Datasette
Zero-code API generation that saves 40-80 hours of development
The handoff: From SQLite file to live API
Layer 1 produced a SQLite file deployed to S3. Now what? How do developers query this data? How do users browse it?
Building a REST API and admin interface from scratch would take weeks. You'd need to:
- Write API endpoints for every table
- Handle pagination, filtering, sorting
- Build a web interface
- Implement search functionality
- Write documentation
Enter Datasette.
What is Datasette?
Datasette is an open-source tool (by Simon Willison) that does one thing brilliantly: turn any SQLite database into an instant API and web interface.
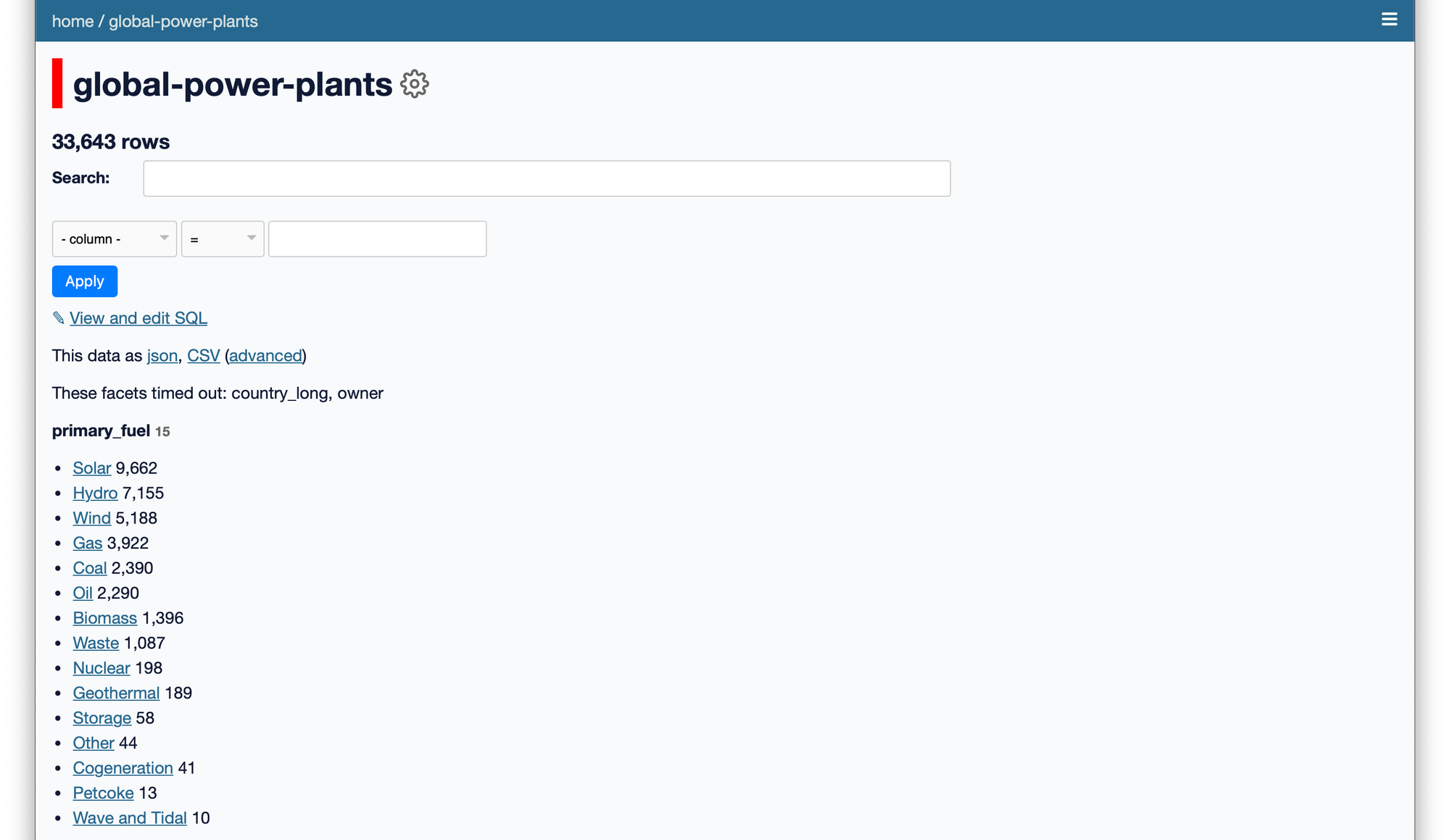
You point it at a SQLite file. It gives you:
- REST API with automatic endpoint generation for every table
- JSON responses with automatic pagination
- Web interface for browsing and querying
- Full-text search (if tables have FTS5 indexes)
- Faceted browsing (filter by categories, dates, etc.)
- SQL query interface for power users
- Zero code written
The deployment architecture:
# Datasette configuration (simplified)
datasette serve \
s3://your-bucket/latest/legal_news_sg.db \
--metadata metadata.json \
--port 8001That's it. Datasette reads the SQLite file directly from S3 and serves it.
What you get automatically:
1. REST API endpoints for every table:
# Get all articles (paginated, default 100 per page)
GET https://data.zeeker.sg/legal_news_sg/articles.json
# Get specific article
GET https://data.zeeker.sg/legal_news_sg/articles/123.json
# Filter by category
GET https://data.zeeker.sg/legal_news_sg/articles.json?category=employment
# Full-text search
GET https://data.zeeker.sg/legal_news_sg/articles.json?_search=unfair+dismissal
# Sort by date, descending
GET https://data.zeeker.sg/legal_news_sg/articles.json?_sort_desc=published_date
# Combine filters
GET https://data.zeeker.sg/legal_news_sg/articles.json?category=employment&_sort_desc=published_date&_size=50Every query parameter is automatically supported. No endpoint code written.
For lawyers: Each of these URLs is a research query you can use directly in your browser. The .json extension means you get structured data back. Copy any URL, paste into your browser, and see the results—no programming required.
2. Interactive web interface:
Browse tables, run searches, filter by facets, export to CSV/JSON - all generated automatically from your database schema. The facets you specified in zeeker add articles --facets category become clickable filters.
3. Full-text search powered by SQLite FTS5:
The zeeker CLI sets up FTS5 indexes automatically when you specify search fields:
# During resource creation
zeeker add articles --fts-fields title --fts-fields contentDatasette exposes the FTS5 search through both API and web interface. No Elasticsearch, no separate search infrastructure needed. SQLite's FTS5 handles hundreds of thousands of records efficiently.
For coders:
- Automatic OpenAPI-style documentation at
/database.json - Clean JSON responses with predictable structure
- Pagination, filtering, sorting built-in
- CORS support for JavaScript clients
- Plugin ecosystem (authentication, caching, custom SQL functions)
- Can embed as Python library or run as standalone service
For lawyers:
- Point-and-click interface for searching legal data
- No SQL knowledge required for basic searches
- Export results to CSV for further analysis in Excel
- Share filtered views via URL (bookmarkable searches)
- Fast search across all articles
The continuous deployment flow:
Scrapers (Python)
→ zeeker build (SQLite file)
→ zeeker deploy (S3)
→ Datasette reads from S3
→ API + Web UI automatically updatedWhen you run zeeker deploy, the new SQLite file replaces the old one in S3. Datasette can be configured to detect the change and reload. Atomic updates with zero API downtime.
Why SQLite + Datasette works:
SQLite files are:
- Portable - single file, easy to deploy
- Fast - optimized for read-heavy workloads (perfect for APIs)
- Queryable - full SQL support including FTS5
- Cacheable - CDNs can cache the entire database file
- Versionable - S3 versioning gives you time-travel for free
Datasette turns these SQLite advantages into developer and user advantages without requiring you to write any API code.
Scaling characteristics:
Datasette serves static database files, so read performance scales horizontally (adding more machines, not bigger machines). You can:
- Add more containers (copies of the application running in parallel)
- Put a CDN in front (content delivery network—essentially a global cache)
No database connection pooling issues. No write concurrency problems. Updates happen via file replacement (zeeker deploy). Static file serving is the cheapest compute pattern.
For data.zeeker.sg with one source, a single container is plenty. If I scale to 40 sources with thousands of articles, I can add containers or put Cloudflare in front. The architecture scales without changing.
The limitation: This is read-only by design. No writes through the API. For a legal news database, that's perfect—scrapers write (via zeeker build), users read (via Datasette). Clear separation of concerns.
Datasette's source code and extensive plugin ecosystem are available at github.com/simonw/datasette—developers can customize templates and styling as needed. For legal professionals, think of it as a specialized web server that speaks database, providing a professional API and search interface without needing to hire a backend developer.
Next layer: Datasette gives you power, but it still expects users to understand tables, fields, and filters. How do you make this accessible to lawyers who don't know what "faceted browsing" means? That's where canned queries come in (Layer 3).
Layer 3: UX Layer - Making It Accessible Without SQL
Progressive disclosure: Search-first for lawyers, full SQL for developers
The handoff: From powerful API to lawyer-friendly interface
Layer 2 gave us Datasette with automatic API endpoints and full-text search. But Datasette's default interface assumes technical users who understand tables, SQL, and APIs.
Lawyers and legal researchers don't think in SQL. They think in research questions: "Find all employment law cases from 2024" or "Show me trends in intellectual property mentions."
The challenge: Bridge the technical-legal divide
I needed to make the database accessible without requiring SQL knowledge, while keeping power available for those who want it.
The solution: Three layers of accessibility.
1. Search-First Interface
Most legal research starts with search, not browsing schemas.
The homepage puts search front and center:

<!-- Prominent search on landing page -->
<input type="search"
placeholder="Search legal news, cases, decisions..."
aria-label="Search legal data">Global search powered by datasette-search-all plugin searches across all databases and tables simultaneously. Lawyers don't need to know which table contains what - just search everything.
2. Use-Case Driven Query Examples
Instead of "here are the SQL commands," I built a "How to Use" guide organized by actual legal research tasks:

Each task includes:
- The method (search or SQL)
- Clickable examples that actually work
- Copy buttons for the code
The legal research goal ("Track legal developments in IP law")
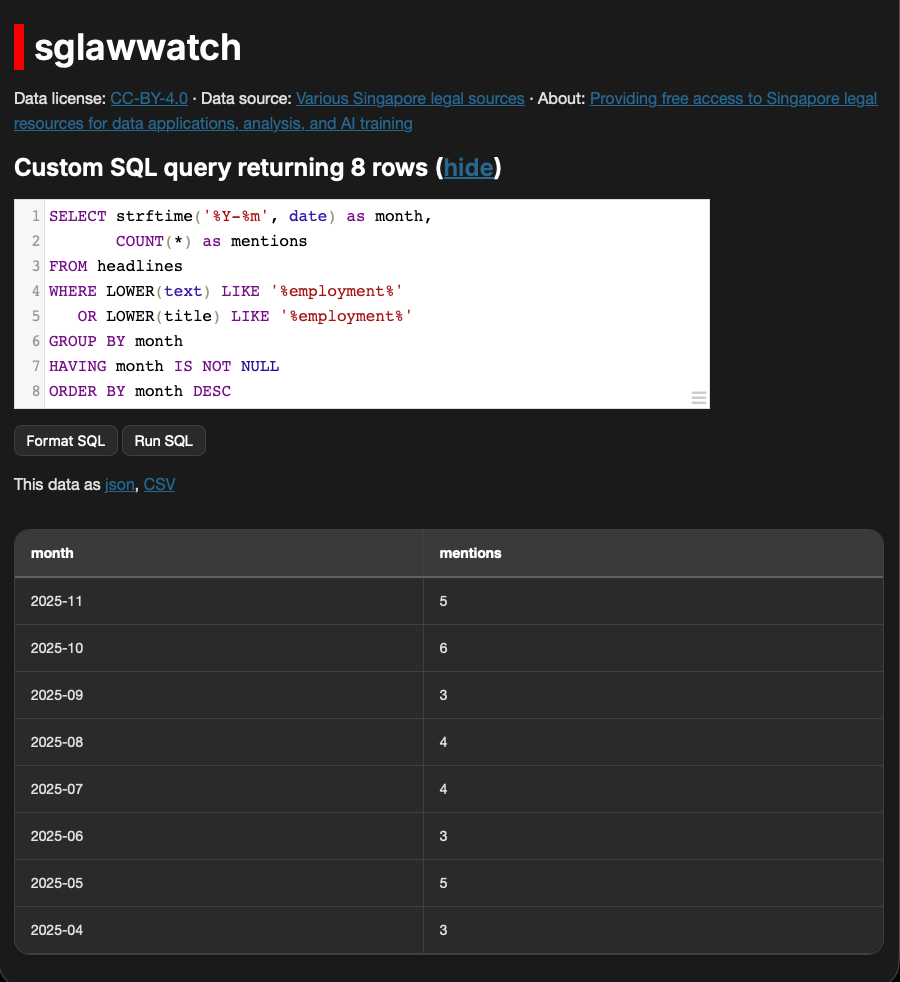
Example task: "Analyze Legal Topic Trends"
-- Clickable query that works immediately
SELECT strftime('%Y-%m', date) as month,
COUNT(*) as mentions
FROM headlines
WHERE LOWER(text) LIKE '%employment%'
OR LOWER(title) LIKE '%employment%'
GROUP BY month
ORDER BY month DESCThe key insight: Every query has a "🔗 Try This Query" button with pre-filled URL parameters. Lawyers can click and see results immediately, then modify the URL to change search terms.
3. JavaScript Enhancements for Usability
⚙️ JavaScript Enhancements (technical details)
Custom JavaScript adds accessibility features:
```
// zeeker-enhanced.js (simplified)
class ZeekerEnhancer {
setupFeatures() {
this.addCopyButtons(); // One-click copy for SQL
this.addKeyboardShortcuts(); // Power user shortcuts
this.setupQueryHelpers(); // Inline SQL assistance
this.setupScrollToTop(); // Long results navigation
}}```
Copy buttons everywhere:
- SQL examples
- API endpoints
- Export URLs
Legal researchers can copy-paste without selecting text.
4. Progressive Disclosure of Complexity
The interface shows three access levels:
Level 1: Search (No SQL required)
🔍 Search box → Type "employment law" → Get results
Export as CSV for Excel analysisLevel 2: Guided SQL (Copy-paste examples)
📊 Pick a use case → Click "Try This Query"
Modify keywords in URLLevel 3: Full SQL (For power users)
💻 SQL Editor → Write custom queries
Full database accessMost lawyers stay at Level 1-2. Researchers and developers use Level 3.
5. Professional Visual Design
🎨 Professional Visual Design (2182 lines of custom CSS)
- Hero banner with Singapore Supreme Court image (contextual branding)
- Glassmorphic cards (modern, professional aesthetic)
- Breadcrumb navigation (never get lost)
- Database/table statistics (understand scope at a glance)
- Responsive design (works on mobile for court/meeting reference)
Custom plugins for polish:
```
String manager plugin - centralized UI text
STRINGS = {
'search_placeholder': 'Search across all legal databases...',
'db_explore': 'Explore Data',
'ui_immutable_data': 'Immutable Data'
}
Template filters - better formatting
env.filters["pluralize"] = pluralize_filter # "1 result" vs "5 results"
env.filters["filesizeformat"] = filesizeformat_filter # "2.5 MB"
```
6. Export-Friendly Everything
Every view has export options visible:
/sglawwatch/headlines.csv → Excel/Google Sheets
/sglawwatch/headlines.json → Python/R/JavaScript
/sglawwatch.db → Full database downloadThe interface serves both audiences simultaneously. Lawyers can search without knowing table names, click pre-built queries, export to Excel, and bookmark filtered searches—no SQL required for 90% of use cases. Developers still have the full SQL interface, documented API endpoints, and JSON/CSV exports on every query, plus copy-paste curl examples:
# From homepage
curl "https://data.zeeker.sg/-/search.json?q=contract+law"The measurement:
Traditional Datasette requires understanding of relational databases, SQL syntax, and API concepts. Enhanced for legal research, users can search, find trends, and export data with zero technical knowledge—SQL available when needed, invisible when not.
Lawyers see a professional legal database, not a developer tool. Developers see Datasette underneath and can query anything they want. Both audiences served by the same infrastructure.
What this enabled: Someone from a law firm could search legal news, export trends to Excel, and share filtered searches with colleagues—without emailing me for help. The interface guides them.
Design Decisions: Why This Architecture?
I've shown you the three layers and how they work together. But why these specific tools? Why not PostgreSQL, FastAPI, or CKAN—the standard tools most developers would reach for?
Each decision optimized for a specific constraint: solo builder, limited budget, legal documents (not just data), passion project sustainability. Let me explain the reasoning.
Why SQLite Instead of PostgreSQL?
Deployment as artifact + zero hosting cost = perfect for solo builders
The standard approach for web applications:
- PostgreSQL database server
- Always-on, accepts writes
- Connection pooling, concurrent access
- Backup strategies, monitoring
- "Production-grade database"
Why I chose SQLite:
- Deployment as artifact: SQLite is a single file. Build it locally, test it, deploy when ready. PostgreSQL is a running service—deploy means migrating data into production.
- Portability: Copy a
.dbfile anywhere. Version it in S3. Download for offline analysis. PostgreSQL requires connection credentials and network access. - Cost: SQLite = zero hosting cost (it's just a file). PostgreSQL = $15-30/month minimum for managed hosting, or maintaining your own server.
- Read-heavy optimization: Legal research is 99.9% reads, 0.1% writes. SQLite excels at read-heavy workloads. PostgreSQL optimizes for concurrent writes I don't need.
- FTS5 full-text search: SQLite's FTS5 extension provides excellent full-text search. No need for Elasticsearch or separate search infrastructure.
The tradeoff: Can't handle concurrent writes. For legal news where all writes happen via scheduled scraper runs (not user input), this limitation doesn't matter.
For solo builders: SQLite means I can develop on my laptop, test everything locally, and deploy only when ready. PostgreSQL means maintaining a production database from day one.
Why Datasette Instead of Custom API?
Automatic API generation saves 40-80 hours (1-2 weeks of full-time work)
Building a custom REST API traditionally means:
- Writing endpoint code for every table (
GET /articles,GET /articles/:id, etc.) - Implementing pagination, filtering, sorting
- Building search functionality
- Writing API documentation
- Handling authentication if needed
- Testing all endpoints
- Maintaining as schema evolves
Conservative estimate: 40-80 hours for basic CRUD API with search.
Datasette provides all of this automatically:
- REST API for every table (zero code)
- Pagination, filtering, sorting (built-in)
- Full-text search (if FTS5 indexes exist)
- Auto-generated documentation
- JSON/CSV exports (every endpoint)
Time saved: 40-80 hours. For a solo builder, that's 1-2 weeks of full-time work.
The flexibility: Datasette is unopinionated about schema. I design the database structure that makes sense for legal news, Datasette serves it.
Why Datasette Instead of CKAN?
Matching tool architecture to operational constraints: When your cloud machine sucks
Before tying out this infrastructure, my first experiment was with CKAN, and I have to say, it's excellent infrastructure. SMU might well choose CKAN for their legal database project (just like data.gov.sg), and for empirical legal research (case statistics, court data, demographic analysis), it may be the right choice.
But CKAN didn't fit my use case. Here's why:
CKAN is opinionated, Datasette is agnostic
CKAN enforces a specific schema:
- Datasets (top-level containers)
- Resources (files attached to datasets)
- Organizations and groups
- Standardized metadata fields (title, publisher, license, format)
- Tags and categories
This schema is optimized for cataloging: "Here's a portal with 100 datasets. Browse metadata, filter by organization, download the CSV/shapefile you need."
Datasette is schema-agnostic:
- You design your database schema
- Datasette serves whatever tables/columns you create
- No prescribed structure
- You decide what makes sense for your data
The use case mismatch
CKAN's catalog model works brilliantly for:
- Crime statistics (CSV datasets)
- Geospatial court jurisdictions (shapefiles)
- Case outcome data (tabular datasets)
- Empirical research collections
Legal researchers browsing: "Which datasets cover employment law statistics? Download and analyze in R."
But legal news/documents need different access patterns:
- Full-text search within article content
- Find all mentions of specific statutes or cases
- Search across potentially millions of words
- Relevance ranking within documents
Legal researchers searching: "Find all articles mentioning 'unfair dismissal' in the last 6 months."
Datasette's flexibility
Because Datasette is agnostic, I could design the right schema:
- Tables for articles with full-text indexes (FTS5)
- Columns optimized for legal metadata (jurisdiction, category, publication date)
- Facets configured for how lawyers actually filter (by court level, legal area, date)
CKAN would force legal content into its dataset/resource model, which doesn't match how legal research works.
The critical infrastructure difference
CKAN is a live application with write operations:
- Users/admins POST data directly to production
- PostgreSQL database receives writes in real-time
- Data processing happens on the live server
- If your cloud machine crashes during data upload or processing, you can corrupt your database
- Requires robust infrastructure to handle concurrent writes safely
- Recovery means database backups and rollback procedures
Datasette + zeeker approach separates build from deployment:
- Build database locally or in GitHub Actions (safe, controlled environment)
- If build fails, retry—production unaffected
- Deploy finished SQLite file to S3 (atomic operation—succeeds or fails cleanly)
- Datasette is read-only in production (no write corruption risk)
- If deploy fails, previous version keeps serving
- Cheap cloud instances work fine because production is just serving static files
For resource-constrained solo builders: CKAN requires infrastructure that can safely handle live writes and data processing. If you're on a $5-10/month container that sometimes struggles, a crash during data upload can corrupt your database.
With Datasette, production is bulletproof—just serving a file. All the risky operations (scraping, data processing, database builds) happen elsewhere (locally, GitHub Actions). Deploy only when data is ready and validated.
CKAN infrastructure requirements:
- Five separate services running simultaneously (database, search, caching, web server, process manager)
- Minimum 4GB RAM
- Needs reliable infrastructure for safe writes
- Designed for institutional scale (hundreds of datasets, multiple organizations)
- Right tool for institutions with proper infrastructure
Datasette infrastructure:
- Single service, read-only production
- Works fine on minimal infrastructure (1-2GB RAM)
- Build/process data anywhere, deploy finished product
- Right tool for solo builders with budget constraints
Where each tool fits
Is SMU building empirical legal database (court statistics, judgment outcomes, demographic analysis)? CKAN's catalog model and institutional credibility make sense. They'll have proper infrastructure.
Solo builder on a budget with unreliable cloud machines? Datasette's read-only production model means you can't corrupt production data no matter what happens.
For data.zeeker.sg: I can't afford robust infrastructure for safe live writes. Building locally, deploying static SQLite files means production is bulletproof even on cheap hosting. If something crashes, the worst case is a failed deploy—previous version keeps running.
This isn't about Datasette being "better"—it's about matching tool architecture to operational constraints. CKAN assumes institutional infrastructure. Datasette works even when your cloud machine sucks.
Why Static Deployment?
Atomic updates, rollback for free, and corruption-proof production
Traditional web application architecture:
- Application server running 24/7
- Database server running 24/7
- Scrapers insert data into live database
- Users query live database
- Worry about concurrent access, caching, database load
Data.zeeker.sg architecture:
- Build SQLite file (locally or GitHub Actions)
- Deploy to S3 (static file hosting)
- Datasette reads from S3 (read-only)
- Scrapers never touch production
Benefits of static deployment:
- Atomic updates: New database file replaces old one completely. Either the new version works, or the old version keeps serving. No partial updates, no corruption risk.
- Rollback for free: S3 versioning keeps old database files. Issue with new data? Revert to previous version instantly.
- CDN-friendly: Static files can be cached aggressively. Put CloudFlare in front for global distribution.
- Zero-downtime deploys: Upload new file to S3, Datasette picks it up. No restart needed (or restart takes seconds).
- Disaster recovery: Database is version-controlled in S3. Any failure? Redeploy from S3.
- Cheap scaling: Serving static files is the cheapest compute pattern. Add more Datasette containers trivially—they all read the same file.
The tradeoff: No real-time user writes. For legal news (scrapers write, users read), this is perfect.
Why This Architecture Enables Open Source Contribution
Isolated development eliminates merge conflicts and dependency hell
The fundamental problem with monolithic data platforms:
It's not just that traditional platforms are complex—it's that they're monolithic. Everyone's code lives in the same codebase.
Monolithic contribution barriers:
- Shared codebase conflicts:
- Your scraper code lives next to everyone else's scrapers
- Merge conflicts when multiple people work simultaneously
- Code review bottleneck (maintainer must review everything)
- Namespace collisions:
- Someone already named their function
parse_article() - Can't use common variable names
- Have to coordinate naming conventions
- Dependency hell:
- Your scraper needs
requests==2.31.0 - Someone else's scraper needs
requests==2.28.0 - Project uses one shared
requirements.txt - Coordinate dependency upgrades across all contributors
- Testing interference:
- Your code might break someone else's tests
- Can't merge until all tests pass
- Even if your scraper works perfectly
- Deployment coordination:
- Can't deploy just your data source
- Have to deploy the entire application
- Your contribution is blocked by someone else's broken code
- Release cycles and deployment windows
Result: Contributing means integrating into the monolith. High friction, slow feedback loops, maintainer bottleneck.
The zeeker architecture: Isolated contribution
Each contributor works in complete isolation:
# Contributor A's isolated project
legal_news_source/
├── pyproject.toml # Their dependencies
├── resources/
│ └── articles.py # Their code
└── legal_news_source.db # Their output
# Contributor B's isolated project
court_decisions_source/
├── pyproject.toml # Different dependencies, no conflict
├── resources/
│ └── decisions.py # Their code
└── court_decisions.db # Their outputNo code integration required:
Contributors don't submit code to a shared repository. They submit:
- A SQLite file (the data)
- Their project repository (for transparency/reproducibility)
The main repository doesn't need to merge their code. It just needs to:
- Download their
.dbfile - Validate it (schema checks, data quality)
- Deploy it to S3
- Datasette automatically serves it
Benefits of architectural isolation:
- No merge conflicts: Everyone works in separate projects
- No namespace collisions: Your project, your names
- No dependency conflicts: Each project has its own
pyproject.toml - No testing interference: Your tests only test your code
- Independent deployment: Deploy your database file without touching anyone else's
- Parallel development: 10 contributors can work simultaneously without coordination
The contribution workflow:
# Contributor develops in isolation
git clone https://github.com/contributor/my-legal-source
cd my-legal-source
zeeker build
# Produces: my-legal-source.db
# Submit to main project
# Option 1: Send the .db file
# Option 2: Main project runs your build automatically (GitHub Actions)
# Main project deploys
aws s3 cp my-legal-source.db s3://bucket/latest/
# Datasette automatically serves the new database
# Zero code changes to productionThe most powerful advantage for open source:
It's not that "the CLI is simpler than PostgreSQL" (though it is). It's that the architecture eliminates code integration entirely. Contributors produce data files, not code to merge.
For open legal data infrastructure, this changes everything. A law student can contribute without being a software engineer. A lawyer can maintain their own data source without coordinating with other contributors.
The single shared codebase is replaced by independent projects, each producing their own data files.
Conclusion
The technical architecture of data.zeeker.sg proves that one person can build sustainable legal data infrastructure with the right architectural choices.
The three layers:
- Data Layer (zeeker CLI) standardizes scraping and deployment
- API Layer (Datasette) provides instant REST API and web interface
- UX Layer (custom CSS/JS) makes it accessible without SQL knowledge
The design decisions:
- SQLite for portability and zero hosting cost
- Datasette for automatic API generation (saving 40-80 hours)
- Static deployment for atomic updates and reliability
- Isolated contribution architecture for open source scalability
The economics:
- Monthly cost: $6-12 (vs. $45-95 for traditional architecture)
- Developer time per source: 2-4 hours (vs. 8-14 hours)
- Maintenance burden: Minimal (just monitor GitHub Actions)
What makes this sustainable for solo builders:
Architecture choices that eliminate ongoing work. Static deployment means production can't be corrupted. CLI standardization means new sources take hours, not days. Datasette means zero API maintenance. GitHub Actions means zero scraper infrastructure.
These aren't just cost savings—they're the difference between feasible and infeasible for a solo builder working evenings and weekends.





Member discussion